TeX users often claim that TeX is better than those word processors, one wonders why there are so few good spell-checkers for TeX documents.
The main reason for this is that TeX documents not only contain "normal" words, but also complex TeX commands. And TeX commands may or may not take parameters, and parameters can be delimited in any imaginable way.
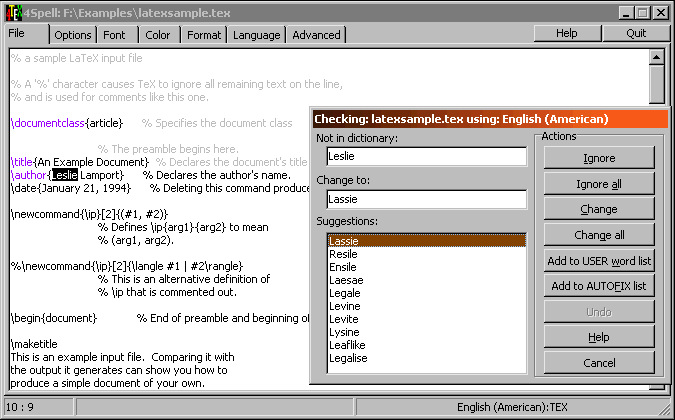
Within certain TeX environments you want the words to be checked (e.g. in tables) and in others you want them to be ignored (e.g. mathematics). All in all a complex situation if you realize that TeX commands, mathematics, and normal words needn't be separated by spaces and line feeds. Any good spell-checker for TeX documents requires a TeX parser that reads the text and decides whether or not a word or a part of the word should be spell-checked. Is writing a parser difficult? The answer probably would be "yes", since there aren't many spell-checkers around. 4Spell proofs that writing such a spell-checker can be done and that it's not that hard to write a spell-checker that can even do more than just TeX.
In September 1998 we had the discussion if we needed to write a spell-checker for 4TeX and concluded that it should be too time consuming to write a good program, since TeX documents are too complex. As often, complex material tends to become much simpler when you have a closer look and spend more time thinking about the structures (TeX is a structured language isn't it). When starting to write 4Spell we started not on the spell-checking routines but on describing how a TeX document should be parsed through the spell-checker. This parsing is the engine of a good spell-checker (and here AmSpell makes it's mistakes). The spell-checking routines were supplied by Aleksander Simonic. Alex is the author of WinEdt, probably the best TeX-aware shareware editor there is for OS/2 and Windows. Cooperation with Alex means that we can all benefit from the same dictionaries, which makes maintenance a lot easier.
In the next section we will describe the parsing of a document, but now we will summarize some of 4Spell's features:
This example $x+y will trigger probblemsCan you predict what will happen if you check your document: it will skip the whole document after the $xy+ since the mathematics isn't ended properly. With AmSpell (or any other spell-checker) you couldn't see this. Now you can see and solve the problem just by looking at the colored document (i.e. everything after the mathematics statement $xy+ is colored as mathematics)!


When you write very long lines and you end end one with a small word you tend to write certain words twice.4Spell will ask you if you want to delete the second "end" entry.
This READWORD procedure is repeated until the end of the file. With these words you need to do a lot of checks before you can spell-check (since a word as defined above can contain (TeX) commands, etc.). Note also (within TeX) the EndOfWord characters are defined as: a space, a hyphen, a tilde, a Carriage-Return, a Line-Feed, and an End-Of-File character.
\begin{skipping}
To explain the spell problem see this example
\begin{skipping}
This won't work if you do not count the number
of begin environments
\end{skipping}
You understand the example?
\end{skipping}
What the spell-checker should do is skip the complete
example above. It should not stop skipping at the first
\end{skipping} command.
When performing the actions above, we were looking for parts of the words. This means that after these actions we will have found (part of) a word preceding the action and (part of) a word after ending the action. With these two words (which may be empty) we proceed as with a word that doesn't trigger one of the actions described above.
,;:.!@#$&*?"%(){}[]-+=0123456789\`~^*_/|'
An example could clarify the meaning of subwords.
Suppose we have the word
\def\hello{\textbf{Hello}}
This will be divided into four subwords:
\def \hello \textbf Hello
It seems easy, but be aware that when building a parser, you will you need to do a lot of bookkeeping, and you will need some more advanced programming tricks (e.g., all word actions and subword actions are recursive procedures).
Published in NTG's
MAPS 22, 1999.
4Spell is free software, which means that you don't
have to pay for using it. The standard GNU public license applies.
You can download it from any CTAN (mirror) site, e.g.
ftp://ftp.ntg.nl/pub/tex-archive/support/4spell/),
or from ftp://4tex.ntg.nl/4spell/.